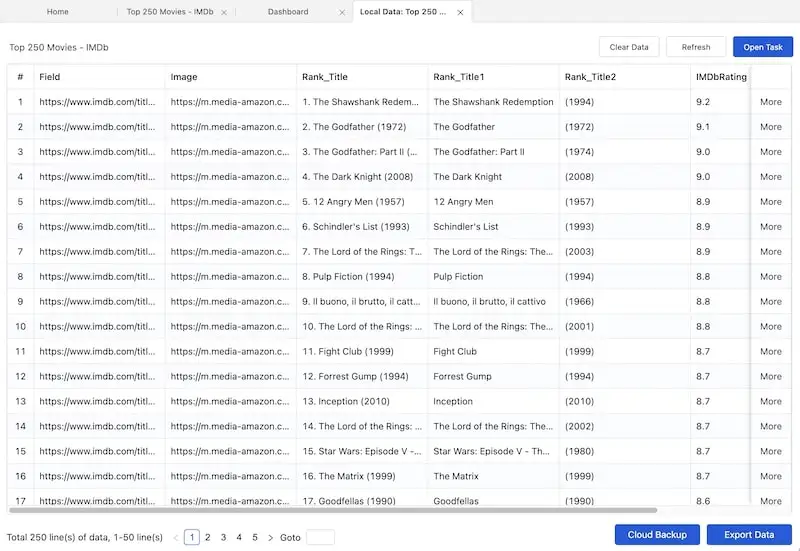
Effortlessly Ascrape Movie Files from IMDb: A Comprehensive Guide
For cinephiles, researchers, and data enthusiasts, the Internet Movie Database (IMDb) is an invaluable resource. Its vast collection of movie data, including cast, crew, plot summaries, ratings, and user reviews, makes it a goldmine for various applications. However, manually extracting this data can be a tedious and time-consuming process. This is where the concept of programmatically accessing and extracting data, or ‘ascraping,’ becomes essential. This article will guide you through the process of using software to ascrape movie files from IMDb, covering the ethical considerations, tools, and techniques involved.
Understanding Web Scraping and IMDb
Web scraping, also known as web harvesting or web data extraction, is the automated process of collecting structured web data. Instead of manually copying and pasting information from websites, web scraping software can intelligently load and extract data from multiple pages. When applied to IMDb, this technique allows users to gather information about movies, actors, directors, and other related data points efficiently.
However, it’s crucial to understand that web scraping isn’t without its ethical and legal boundaries. Most websites, including IMDb, have terms of service that outline acceptable use. While scraping publicly available data is often considered fair use, overloading servers or circumventing access restrictions can lead to legal repercussions. Always review the website’s robots.txt file and terms of service before initiating any scraping activities.
Tools and Technologies for Ascraping Movie Files from IMDb
Several tools and programming languages are available for ascraping movie files from IMDb. The choice depends on your technical skills, project requirements, and preferred level of control. Here are some popular options:
Python with Beautiful Soup and Requests
Python is a versatile and widely used programming language for web scraping. Its clear syntax and extensive libraries make it an excellent choice for beginners and experienced developers alike. Two key libraries for ascraping movie files from IMDb using Python are:
- Requests: This library allows you to send HTTP requests to IMDb’s servers and retrieve the HTML content of web pages.
- Beautiful Soup: This library parses the HTML content, making it easy to navigate and extract specific data elements.
Here’s a simplified example of how you might use these libraries to scrape movie titles from an IMDb search results page:
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/search/title/?genres=action&sort=user_rating,desc&title_type=feature"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
movie_titles = soup.find_all('h3', class_='lister-item-header')
for title in movie_titles:
print(title.a.text)
This code snippet retrieves the HTML content of an IMDb search page, parses it using Beautiful Soup, and then extracts the movie titles from the `h3` tags with the class `lister-item-header`. The `.a.text` part accesses the text within the `` tag inside the `
` tag, which contains the actual movie title. This demonstrates a basic approach to ascrape movie files from IMDb.
Scrapy
Scrapy is a powerful and flexible Python framework designed specifically for web scraping. It provides a comprehensive set of tools for handling complex scraping tasks, including:
- Automatic request handling: Scrapy manages the process of sending HTTP requests and handling responses.
- Data extraction: Scrapy uses CSS selectors and XPath expressions to extract data from HTML and XML documents.
- Data pipelines: Scrapy allows you to process and store scraped data in various formats, such as CSV, JSON, or databases.
- Middleware: Scrapy provides middleware for handling tasks such as user-agent rotation, proxy management, and request throttling.
Scrapy is particularly well-suited for large-scale scraping projects that require advanced features and customization. It allows for creating spiders that can automatically navigate through multiple pages of IMDb, following links and extracting data along the way. This makes it easier to ascrape movie files from IMDb in a structured and efficient manner.
Selenium
Selenium is a browser automation tool that can be used for web scraping. Unlike Requests and Beautiful Soup, which directly parse HTML content, Selenium controls a web browser (such as Chrome or Firefox) to interact with web pages. This is particularly useful for scraping websites that rely heavily on JavaScript, as Selenium can execute JavaScript code and retrieve the rendered HTML content.
Selenium is more resource-intensive than other scraping methods, as it requires running a full web browser. However, it can be essential for ascraping movie files from IMDb when dealing with dynamic content or when you need to simulate user interactions, such as clicking buttons or filling out forms.
Other Tools
Besides the tools mentioned above, several other options are available for web scraping, including:
- Octoparse: A visual web scraping tool that allows you to extract data without writing any code.
- ParseHub: Another visual web scraping tool with a user-friendly interface.
- Import.io: A cloud-based web scraping platform that provides a range of features for data extraction and analysis.
Steps to Ascrape Movie Files from IMDb
Here’s a general outline of the steps involved in ascraping movie files from IMDb:
- Identify your data needs: Determine what specific data points you want to extract from IMDb (e.g., movie titles, ratings, genres, cast information).
- Choose your scraping tool: Select the appropriate tool or programming language based on your technical skills and project requirements.
- Inspect the IMDb website: Use your browser’s developer tools to examine the HTML structure of IMDb pages and identify the CSS selectors or XPath expressions that correspond to the data you want to extract.
- Write your scraping code: Develop the code to send HTTP requests to IMDb, parse the HTML content, and extract the desired data.
- Implement error handling: Add error handling to your code to gracefully handle unexpected issues, such as network errors or changes to the IMDb website structure.
- Respect IMDb’s terms of service: Throttle your requests to avoid overloading IMDb’s servers, and adhere to their robots.txt file.
- Store the scraped data: Save the extracted data in a suitable format, such as CSV, JSON, or a database.
Ethical Considerations and Legal Compliance
As mentioned earlier, it’s crucial to approach web scraping ethically and legally. Here are some key considerations:
- Review IMDb’s terms of service: Familiarize yourself with IMDb’s terms of service and ensure that your scraping activities comply with their guidelines.
- Respect robots.txt: The robots.txt file specifies which parts of the website should not be accessed by web crawlers. Adhere to these directives to avoid overloading their servers.
- Throttle your requests: Avoid sending too many requests in a short period of time, as this can overload IMDb’s servers and potentially lead to your IP address being blocked. Implement delays between requests to simulate human browsing behavior.
- Identify yourself: Include a user-agent header in your HTTP requests to identify your scraper. This allows IMDb to contact you if they have any concerns.
- Use the data responsibly: Ensure that you use the scraped data ethically and in accordance with any applicable laws and regulations. Avoid using the data for malicious purposes, such as spamming or harassment.
Advanced Techniques for Ascraping Movie Files from IMDb
For more complex scraping scenarios, you may need to employ advanced techniques, such as:
- User-agent rotation: Rotate your user-agent header to avoid being identified and blocked by IMDb.
- Proxy management: Use proxy servers to mask your IP address and distribute your requests across multiple servers.
- CAPTCHA solving: Implement CAPTCHA solving techniques to bypass CAPTCHAs that may be presented by IMDb.
- Data cleaning and transformation: Clean and transform the scraped data to ensure that it is accurate and consistent.
These techniques can help you overcome challenges and improve the reliability of your scraping activities. However, they also require more technical expertise and can be more complex to implement. Remember to always prioritize ethical considerations and legal compliance when using these advanced techniques to ascrape movie files from IMDb.
Practical Applications of Ascraped Movie Data
The data extracted by ascraping movie files from IMDb can be used for a wide range of applications, including:
- Movie recommendation systems: Building personalized movie recommendation systems based on user preferences and movie attributes.
- Sentiment analysis: Analyzing user reviews to gauge the overall sentiment towards a movie.
- Market research: Conducting market research to identify trends and patterns in the movie industry.
- Data visualization: Creating visualizations to explore and communicate insights from movie data.
- Academic research: Conducting academic research on various aspects of the movie industry, such as box office performance, genre trends, and actor popularity.
By leveraging the power of web scraping, you can unlock valuable insights from IMDb’s vast database and create innovative applications that enhance the movie-watching experience.
Conclusion
Ascraping movie files from IMDb can be a powerful tool for data analysis, research, and application development. By understanding the ethical considerations, utilizing the appropriate tools and techniques, and respecting IMDb’s terms of service, you can effectively extract valuable data from this invaluable resource. Whether you’re building a movie recommendation system, conducting market research, or simply exploring the world of cinema, web scraping can help you unlock the full potential of IMDb’s vast database. Remember to always prioritize ethical and legal compliance, and use the data responsibly to create positive and impactful applications. [See also: Web Scraping Best Practices] [See also: Legal Aspects of Web Scraping]
