Mastering Web Scraping with Scrapy: A Comprehensive Guide
In today’s data-driven world, the ability to extract information from the web is a crucial skill. Web scraping, the automated process of collecting data from websites, has become an indispensable tool for researchers, analysts, and businesses alike. Among the various web scraping frameworks available, Scrapy stands out as a powerful and versatile option. This comprehensive guide will delve into the intricacies of web scraping with Scrapy, covering everything from installation to advanced techniques.
What is Scrapy?
Scrapy is an open-source, collaborative framework for extracting the data you need from websites. In a nutshell, it provides all the tools you need to efficiently extract data, process it as you want, and store it in your preferred structure and storage. Written in Python, Scrapy is designed for large-scale web scraping projects and is known for its speed, flexibility, and ease of use. It follows the “Don’t Repeat Yourself” (DRY) principle, encouraging reusable code and a clean project structure. Scrapy is not just a library; it’s a complete framework with built-in features for handling common web scraping tasks, such as managing requests, handling cookies, and parsing HTML and XML.
Why Use Scrapy for Web Scraping?
Several factors contribute to Scrapy’s popularity as a web scraping framework:
- Speed and Efficiency: Scrapy is built on top of Twisted, an asynchronous network programming framework, allowing it to handle multiple requests concurrently. This makes it significantly faster than traditional synchronous scraping methods.
- Flexibility: Scrapy’s architecture allows for customization at every stage of the scraping process. You can easily modify the request pipeline, data processing, and storage mechanisms to suit your specific needs.
- Extensibility: Scrapy has a rich ecosystem of extensions and middleware that provide additional functionalities, such as handling proxies, managing user agents, and dealing with CAPTCHAs.
- Built-in Features: Scrapy comes with built-in support for common web scraping tasks, including CSS selectors, XPath expressions, and data serialization formats like JSON and CSV.
- Community Support: Scrapy has a large and active community of users and developers who contribute to its ongoing development and provide support to newcomers.
Getting Started with Scrapy: Installation and Setup
Before you can start web scraping with Scrapy, you need to install it on your system. Scrapy requires Python (version 3.7 or higher) to be installed. It is highly recommended to use a virtual environment to isolate your project dependencies.
Installing Scrapy
To install Scrapy, you can use pip, the Python package installer:
pip install scrapyThis command will download and install Scrapy and its dependencies. Once the installation is complete, you can verify it by running:
scrapy versionThis should display the installed version of Scrapy.
Creating a Scrapy Project
To start a new Scrapy project, use the scrapy startproject command:
scrapy startproject myprojectThis will create a directory named myproject with the following structure:
myproject/
scrapy.cfg # deploy configuration file
myproject/
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you will later put your spiders
__init__.py
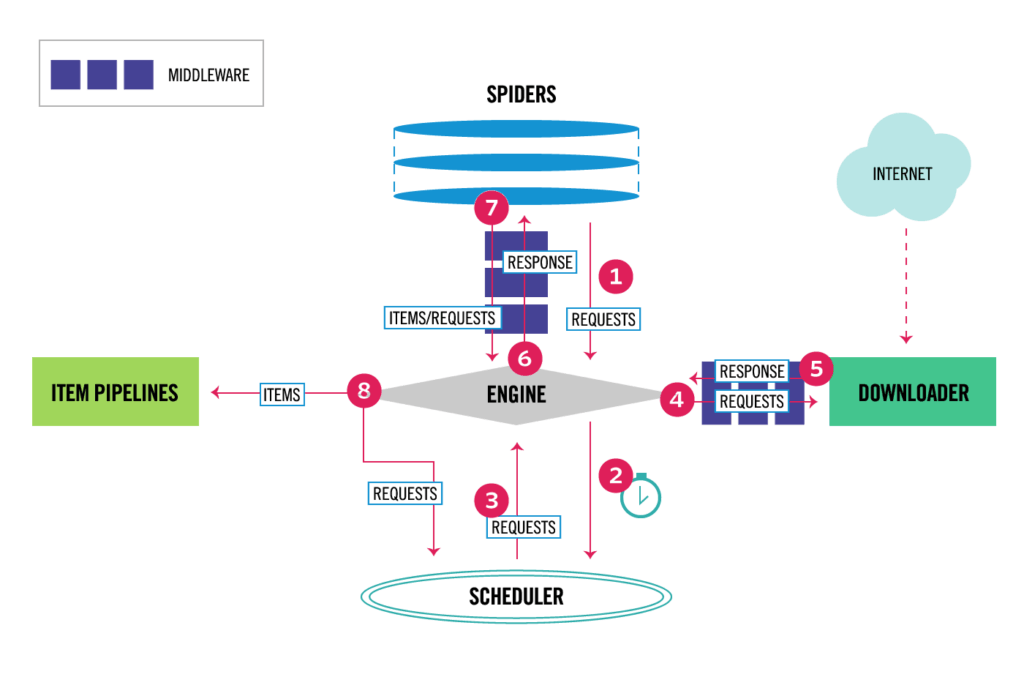
Understanding Scrapy Architecture
Scrapy’s architecture is based on a component-based design, with several key components working together to extract data from websites. Understanding these components is essential for effectively using Scrapy for web scraping.
- Spiders: Spiders are the heart of Scrapy. They define how to crawl a specific website and extract data from its pages. You define the starting URLs, how to follow links, and how to extract data from each page.
- Scrapy Engine: The engine is the core of Scrapy, responsible for coordinating the other components. It manages the flow of requests and responses, scheduling tasks, and handling errors.
- Scheduler: The scheduler receives requests from the engine and decides when to send them to the Downloader. It also handles request prioritization and deduplication.
- Downloader: The downloader is responsible for fetching web pages from the internet. It handles HTTP requests, manages cookies, and handles redirects.
- Spider Middleware: Spider middleware provides a hook into the spider processing mechanism, allowing you to modify requests and responses before they reach the spider.
- Downloader Middleware: Downloader middleware provides a hook into the downloader processing mechanism, allowing you to modify requests and responses before they are sent to the spider.
- Item Pipeline: The item pipeline is responsible for processing the data extracted by the spiders. It can be used to clean, validate, and store the data in a database or other storage system.
Creating Your First Scrapy Spider
Let’s create a simple spider that extracts the titles of articles from a blog. First, navigate to the spiders directory in your Scrapy project and create a new file named blog_spider.py.
Here’s the code for the spider:
import scrapy
class BlogSpider(scrapy.Spider):
name = "blogspider"
start_urls = [
'https://blog.example.com/'
]
def parse(self, response):
for title in response.css('h2 a'):
yield {
'title': title.css('a ::text').get(),
'link': title.css('a ::attr(href)').get()
}
In this example:
name: Defines the name of the spider, which is used to run it.start_urls: A list of URLs that the spider will start crawling from.parse: A callback function that is called for each downloaded page. It extracts the titles and links of the articles and yields them as dictionaries.
Running the Spider
To run the spider, use the scrapy crawl command:
scrapy crawl blogspiderThis will start the spider and print the extracted data to the console. You can also save the data to a file using the -o option:
scrapy crawl blogspider -o output.jsonThis will save the extracted data to a file named output.json in JSON format.
Using CSS Selectors and XPath Expressions
Scrapy supports both CSS selectors and XPath expressions for selecting elements from HTML and XML documents. CSS selectors are a more concise and readable way to select elements, while XPath expressions provide more flexibility and power.
CSS Selectors
CSS selectors use the same syntax as CSS stylesheets. For example, to select all h2 elements with a class of title, you would use the following selector:
h2.titleTo select all links within an h2 element, you would use the following selector:
h2 aXPath Expressions
XPath expressions use a more complex syntax to select elements. For example, to select all h2 elements with a class of title, you would use the following expression:
//h2[@class="title"]To select all links within an h2 element, you would use the following expression:
//h2/aChoosing between CSS selectors and XPath expressions depends on your personal preference and the complexity of the selection task. CSS selectors are generally easier to learn and use for simple tasks, while XPath expressions are more powerful for complex tasks. Mastering web scraping with Scrapy often involves becoming proficient in both.
Handling Pagination
Many websites use pagination to break up long lists of items into multiple pages. To scrape all the items from a paginated website, you need to follow the links to the next pages. Scrapy provides a convenient way to handle pagination using the CrawlSpider class and the LinkExtractor class.
Using CrawlSpider and LinkExtractor
The CrawlSpider class is a specialized spider that is designed for crawling websites with pagination. It uses the LinkExtractor class to find links to follow. Here’s an example of how to use CrawlSpider and LinkExtractor to scrape a paginated website:
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'myspider'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com/']
rules = (
Rule(LinkExtractor(allow=r'/page/d+/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
# Extract data from the page
pass
In this example:
allowed_domains: A list of domains that the spider is allowed to crawl.rules: A list of rules that define how to follow links. In this case, the rule usesLinkExtractorto find links that match the regular expression/page/d+/(e.g.,/page/1/,/page/2/, etc.). Thecallbackargument specifies the callback function to be called for each downloaded page, and thefollowargument specifies whether to follow the links on the page.
Using Item Pipelines
Item pipelines are used to process the data extracted by the spiders. They can be used to clean, validate, and store the data in a database or other storage system. To use an item pipeline, you need to define a class that inherits from scrapy.ItemPipeline and implement the process_item method.
Defining an Item Pipeline
Here’s an example of an item pipeline that validates the extracted data and saves it to a JSON file:
import json
class JsonWriterPipeline:
def open_spider(self, spider):
self.file = open('items.json', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "n"
self.file.write(line)
return item
In this example:
open_spider: A method that is called when the spider is opened. It opens the file to write the data to.close_spider: A method that is called when the spider is closed. It closes the file.process_item: A method that is called for each extracted item. It converts the item to a JSON string and writes it to the file.
Enabling the Item Pipeline
To enable the item pipeline, you need to add it to the ITEM_PIPELINES setting in your Scrapy project’s settings.py file:
ITEM_PIPELINES = {
'myproject.pipelines.JsonWriterPipeline': 300,
}
The number 300 specifies the order in which the pipelines are executed. Lower numbers are executed first.
Handling Dynamic Content with Selenium
Some websites use JavaScript to generate content dynamically. Scrapy is not able to execute JavaScript code, so it cannot scrape these websites directly. To scrape dynamic content, you can use Selenium, a web automation framework that can execute JavaScript code in a browser. Selenium can be integrated with Scrapy to handle dynamic content. Web scraping with Scrapy becomes even more powerful with this integration.
Integrating Selenium with Scrapy
To integrate Selenium with Scrapy, you need to install Selenium and a browser driver (e.g., ChromeDriver for Chrome):
pip install selenium
# Download ChromeDriver from https://chromedriver.chromium.org/downloadsThen, you need to create a downloader middleware that uses Selenium to fetch the page content:
from scrapy import signals
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
class SeleniumMiddleware:
@classmethod
def from_crawler(cls, crawler):
middleware = cls()
crawler.signals.connect(middleware.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(middleware.spider_closed, signal=signals.spider_closed)
return middleware
def process_request(self, request, spider):
chrome_options = Options()
chrome_options.add_argument("--headless") # Run Chrome in headless mode
self.driver = webdriver.Chrome(options=chrome_options)
self.driver.get(request.url)
body = self.driver.page_source
return scrapy.http.HtmlResponse(self.driver.current_url, body=body, encoding='utf-8', request=request)
def spider_opened(self, spider):
pass
def spider_closed(self, spider):
self.driver.quit()
Finally, you need to enable the downloader middleware in your Scrapy project’s settings.py file:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.SeleniumMiddleware': 543,
}
With this setup, Scrapy will use Selenium to fetch the page content for all requests, allowing you to scrape dynamic content. [See also: Introduction to Selenium Webdriver]
Best Practices for Web Scraping with Scrapy
To ensure that your web scraping projects are successful and ethical, it’s important to follow some best practices:
- Respect Robots.txt: The
robots.txtfile specifies which parts of a website should not be crawled. Always respect the rules defined in this file. - Use Polite Crawling: Avoid overloading the website’s server by sending too many requests in a short period of time. Use the
DOWNLOAD_DELAYsetting in Scrapy to introduce a delay between requests. - Use User Agents: Set a realistic user agent in your Scrapy project’s
settings.pyfile. This helps to identify your scraper to the website and avoid being blocked. - Handle Errors Gracefully: Implement error handling in your spiders to gracefully handle unexpected errors, such as network errors or changes in the website’s structure.
- Store Data Efficiently: Choose an appropriate storage format for your extracted data, such as JSON, CSV, or a database. [See also: Choosing the Right Database for Your Project]
- Monitor Your Scraper: Monitor your scraper’s performance and error rate to ensure that it is working correctly.
- Comply with Legal Requirements: Ensure that you comply with all applicable legal requirements, such as copyright laws and data privacy regulations.
Advanced Techniques for Web Scraping with Scrapy
Once you have mastered the basics of web scraping with Scrapy, you can explore some advanced techniques to improve your scraper’s performance and robustness:
- Using Proxies: Use proxies to hide your scraper’s IP address and avoid being blocked by the website.
- Handling CAPTCHAs: Implement CAPTCHA solving techniques to bypass CAPTCHAs and continue scraping.
- Using Scrapy Splash: Use Scrapy Splash, a JavaScript rendering service, to handle dynamic content more efficiently than Selenium.
- Using Scrapy Cloud: Use Scrapy Cloud, a cloud-based platform for running and managing Scrapy spiders.
Conclusion
Web scraping with Scrapy is a powerful and versatile technique for extracting data from the web. By understanding Scrapy’s architecture, mastering its core components, and following best practices, you can build robust and efficient scrapers that can extract valuable data from any website. Whether you’re a researcher, analyst, or business professional, Scrapy can help you unlock the vast potential of the web’s data. This guide provides a solid foundation for getting started with Scrapy and exploring its advanced capabilities. Happy scraping! [See also: Advanced Web Scraping Techniques]
