Parse What Is: A Comprehensive Guide to Parsing Data
In the realm of computer science and data processing, the ability to parse what is presented is fundamental. Parsing, at its core, is the process of transforming raw data into a structured, understandable format that can be used by computers or humans. This article delves into the intricacies of parsing, exploring its definition, applications, methodologies, and the tools used in this critical process. Understanding parse what is and how it works is essential for anyone working with data, whether it’s a programmer, data analyst, or even a business professional.
Understanding the Fundamentals of Parsing
Parsing involves taking an input, which can be text, code, or any other form of data, and analyzing it according to a set of rules or grammar. The goal is to break down the input into its constituent parts and understand its structure. This structured representation then allows for further processing, such as interpretation, compilation, or data extraction. When we parse what is available, we aim to extract meaningful information.
The Definition of Parsing
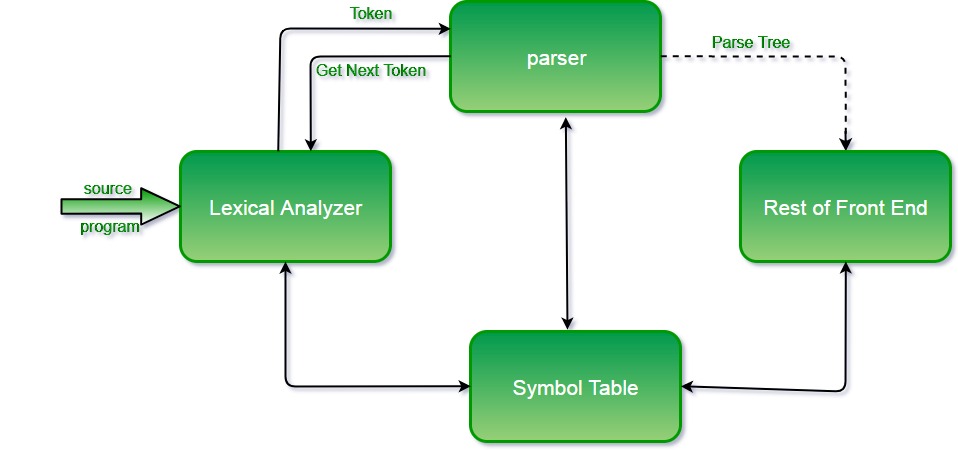
Parsing, in the context of computer science, is defined as the process of analyzing a string of symbols, either in natural language, computer languages, or data structures, conforming to the rules of a formal grammar. A parser is a software component that performs this analysis. The output of a parser is typically a parse tree, also known as a syntax tree, which represents the grammatical structure of the input.
Why is Parsing Important?
Parsing is crucial for several reasons:
- Language Processing: Compilers and interpreters rely on parsing to understand and execute code.
- Data Extraction: Parsing enables the extraction of specific data points from unstructured or semi-structured data sources.
- Data Validation: Parsing can be used to validate the format and structure of data, ensuring its integrity.
- Data Transformation: Parsed data can be transformed into different formats for various applications.
Applications of Parsing
The applications of parsing are vast and varied, spanning numerous industries and domains. Let’s explore some key areas where parsing plays a vital role.
Programming Languages and Compilers
One of the most well-known applications of parsing is in the construction of compilers and interpreters for programming languages. When a programmer writes code, the compiler needs to understand the syntax and semantics of the code to translate it into machine-executable instructions. This is where parsing comes in. The compiler uses a parser to analyze the code, identify its components (e.g., variables, operators, control structures), and build a syntax tree. This syntax tree is then used for further processing, such as optimization and code generation. Without the ability to parse what is written, a compiler couldn’t translate human-readable code into machine code.
Data Analysis and Extraction
In the realm of data analysis, parsing is essential for extracting meaningful information from unstructured or semi-structured data sources. For example, consider a large text file containing customer reviews. To analyze the sentiment of these reviews, you would need to parse what is written to identify the key words, phrases, and sentiment indicators. This can be achieved using techniques like natural language processing (NLP) and regular expressions. Parsing allows you to transform the raw text data into a structured format that can be analyzed using statistical methods or machine learning algorithms.
Web Scraping
Web scraping involves extracting data from websites. Websites are typically structured using HTML, which is a markup language. To extract specific data points from a website, you need to parse what is HTML code. This involves identifying the relevant HTML tags and attributes that contain the desired data. Tools like Beautiful Soup and Scrapy are commonly used for web scraping, as they provide functionalities for parsing HTML and extracting data. By using these tools, it’s possible to parse what is on a website and pull valuable data.
Configuration Files
Many software applications rely on configuration files to store settings and parameters. These configuration files are often written in formats like JSON, XML, or YAML. To read and use the settings stored in these files, the application needs to parse what is written. Parsers for these formats are readily available in most programming languages, allowing applications to easily access and utilize the configuration data.
Network Protocols
Network protocols, such as HTTP and SMTP, define the rules for communication between computers over a network. These protocols involve sending and receiving messages in specific formats. To understand and process these messages, computers need to parse what is being transmitted. This involves analyzing the message headers, body, and other components according to the protocol specification.
Methodologies and Techniques for Parsing
Various methodologies and techniques are employed in parsing, each suited to different types of input and parsing requirements.
Lexical Analysis
Lexical analysis, also known as scanning, is the first phase of parsing. It involves breaking down the input stream into a sequence of tokens. A token is a meaningful unit of the input, such as a keyword, identifier, operator, or literal. The lexical analyzer identifies these tokens based on predefined patterns or regular expressions. For example, in a programming language, the lexical analyzer would identify keywords like `if`, `else`, and `while`, as well as variable names and operators like `+` and `-`. The output of the lexical analyzer is a stream of tokens that is passed to the next phase, the syntax analyzer.
Syntax Analysis
Syntax analysis, also known as parsing (in a narrower sense), is the second phase of parsing. It involves analyzing the sequence of tokens produced by the lexical analyzer and constructing a syntax tree. The syntax tree represents the grammatical structure of the input according to the rules of a formal grammar. The syntax analyzer uses a parser to perform this analysis. Different types of parsers exist, each with its own strengths and weaknesses. Some common types of parsers include:
- Top-Down Parsers: These parsers start with the root of the syntax tree and work their way down to the leaves. Examples include recursive descent parsers and LL parsers.
- Bottom-Up Parsers: These parsers start with the leaves of the syntax tree and work their way up to the root. Examples include LR parsers and shift-reduce parsers.
Semantic Analysis
Semantic analysis is the third phase of parsing. It involves checking the meaning and consistency of the syntax tree. This includes tasks like type checking, scope resolution, and ensuring that the code adheres to the language’s semantic rules. For example, the semantic analyzer would check that variables are used correctly, that functions are called with the correct arguments, and that type conversions are performed appropriately. The output of the semantic analyzer is an annotated syntax tree that contains additional information about the meaning of the code. When we successfully parse what is written, it’s not just about syntax; we’re looking for meaning.
Tools for Parsing
Numerous tools and libraries are available to assist with parsing, each offering different features and capabilities.
Lex and Yacc
Lex and Yacc are classic tools for building lexical analyzers and parsers, respectively. Lex is a lexical analyzer generator that takes a set of regular expressions as input and generates a C program that performs lexical analysis. Yacc is a parser generator that takes a formal grammar as input and generates a C program that performs syntax analysis. Lex and Yacc are widely used in the development of compilers and interpreters.
ANTLR
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator that supports a wide range of programming languages. ANTLR takes a grammar as input and generates a parser for that grammar. ANTLR also provides support for lexical analysis, syntax analysis, and semantic analysis. It’s a popular choice for building language processors, compilers, and interpreters. Being able to effectively parse what is required from a language is a key function of ANTLR.
Regular Expressions
Regular expressions are a powerful tool for pattern matching and text processing. They can be used to parse what is a simple text format or to extract specific data points from a larger text. Most programming languages provide built-in support for regular expressions, making them a versatile tool for parsing tasks.
JSON Parsers
JSON (JavaScript Object Notation) is a widely used data format for exchanging data between applications. Most programming languages provide libraries for parsing JSON data. These libraries allow you to easily read and write JSON data, as well as to access specific data points within the JSON structure. These tools help to parse what is in a JSON format and convert it to a usable data structure.
XML Parsers
XML (Extensible Markup Language) is another popular data format for storing and exchanging data. Similar to JSON, most programming languages provide libraries for parsing XML data. These libraries allow you to navigate the XML structure, extract data, and modify the XML document. Successfully using these tools helps to parse what is contained within an XML file.
Challenges and Considerations in Parsing
While parsing is a fundamental process, it also presents several challenges and considerations.
Ambiguity
Ambiguity arises when a grammar allows for multiple possible parse trees for the same input. This can lead to incorrect or unpredictable parsing results. To address ambiguity, grammars need to be carefully designed to ensure that there is only one valid parse tree for any given input.
Error Handling
Error handling is a critical aspect of parsing. When the input does not conform to the grammar, the parser needs to detect and report errors in a clear and informative manner. Good error handling can help users identify and correct errors in their input, improving the overall user experience. The goal is to clearly parse what is incorrect and provide useful information.
Performance
Parsing can be a computationally intensive process, especially for large inputs or complex grammars. Optimizing the performance of the parser is crucial for ensuring that it can handle the workload efficiently. Techniques like memoization, caching, and parallelization can be used to improve parsing performance.
Security
Parsing can be a potential security risk if the input is not properly validated. Malicious input can exploit vulnerabilities in the parser, leading to security breaches. It’s important to sanitize and validate the input before parsing it to prevent such attacks. This is especially important when you parse what is coming from external sources.
Conclusion
Parsing is a fundamental process in computer science and data processing, enabling the transformation of raw data into a structured, understandable format. Its applications span various domains, from programming languages and compilers to data analysis and web scraping. By understanding the methodologies, techniques, and tools involved in parsing, you can effectively process and analyze data to extract valuable insights. Whether you’re a programmer, data analyst, or business professional, mastering the art of parsing is essential for success in today’s data-driven world. The ability to efficiently and accurately parse what is presented is a crucial skill. [See also: Understanding Data Structures] [See also: Introduction to Algorithms]
