Scrape Google Finance with Python: A Comprehensive Guide
In today’s data-driven world, access to real-time financial information is crucial for investors, analysts, and researchers. Google Finance provides a wealth of data, including stock prices, historical data, and company financials. However, manually extracting this data can be time-consuming and inefficient. Fortunately, Python offers powerful tools and libraries to automate the process of scraping Google Finance. This article provides a comprehensive guide on how to scrape Google Finance with Python, covering everything from setting up your environment to handling common challenges.
Why Scrape Google Finance with Python?
Efficiency: Automating data extraction saves significant time and effort compared to manual methods.
Real-time Data: Obtain up-to-date financial data for timely analysis and decision-making.
Customization: Tailor the scraping process to extract specific data points relevant to your needs.
Integration: Seamlessly integrate scraped data into your existing analytical workflows and models.
Scalability: Easily scale your data collection efforts as your needs grow.
Setting Up Your Environment
Before you begin, ensure you have Python installed on your system. It’s also recommended to use a virtual environment to manage dependencies. Here’s how to set up your environment:
- Install Python: Download and install the latest version of Python from the official Python website.
- Create a Virtual Environment: Open your terminal or command prompt and navigate to your project directory. Then, create a virtual environment using the following command:
python -m venv venv - Activate the Virtual Environment:
- On Windows:
venvScriptsactivate - On macOS and Linux:
source venv/bin/activate
- On Windows:
- Install Required Libraries: Use pip to install the necessary libraries:
pip install requests beautifulsoup4 pandas- requests: For making HTTP requests to fetch the HTML content of web pages.
- beautifulsoup4: For parsing HTML and XML documents.
- pandas: For data manipulation and analysis.
Understanding Google Finance’s Structure
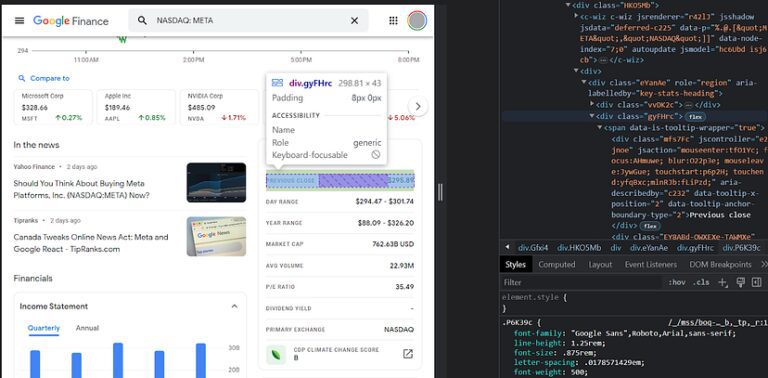
Before you start scraping, it’s essential to understand the structure of Google Finance’s web pages. Inspect the HTML source code to identify the elements containing the data you want to extract. Use your browser’s developer tools (usually accessible by pressing F12) to examine the HTML structure and identify relevant tags and classes.
For example, if you want to scrape Google Finance with Python for the current stock price of Apple (AAPL), you would navigate to the AAPL page on Google Finance and inspect the element containing the price. You’ll typically find that the price is within a specific HTML tag, such as a <div> or <span> tag, with a particular class or ID.
Basic Scraping with Requests and BeautifulSoup
Here’s a basic example of how to scrape Google Finance with Python using the requests and beautifulsoup4 libraries:
import requests
from bs4 import BeautifulSoup
def scrape_google_finance(ticker):
url = f'https://www.google.com/finance/quote/{ticker}:US'
response = requests.get(url)
response.raise_for_status() # Raise HTTPError for bad responses (4xx or 5xx)
soup = BeautifulSoup(response.content, 'html.parser')
# Example: Extract the current price
price_element = soup.find('div', class_='kf1m0')
if price_element:
price = price_element.text
print(f'Current price of {ticker}: {price}')
else:
print(f'Price not found for {ticker}')
# Example usage
ticker_symbol = 'AAPL'
scrape_google_finance(ticker_symbol)
This code snippet fetches the HTML content of the Google Finance page for a given ticker symbol and uses BeautifulSoup to parse the HTML. It then searches for the element containing the current price (identified by the class kf1m0) and extracts the text.
Handling Dynamic Content with Selenium
Some Google Finance pages use JavaScript to dynamically load content. In such cases, the requests library alone may not be sufficient, as it only fetches the initial HTML source code. To handle dynamic content, you can use Selenium, a browser automation tool.
Here’s how to scrape Google Finance with Python using Selenium:
- Install Selenium:
pip install selenium - Download a WebDriver: Selenium requires a WebDriver to interact with a browser. Download the appropriate WebDriver for your browser (e.g., ChromeDriver for Chrome) from the official Selenium website or the browser vendor’s website.
- Configure Selenium: Specify the path to the WebDriver in your code.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def scrape_google_finance_selenium(ticker):
chrome_options = Options()
chrome_options.add_argument("--headless") # Run Chrome in headless mode
# Replace with the actual path to your ChromeDriver executable
webdriver_path = '/path/to/chromedriver'
service = Service(executable_path=webdriver_path)
driver = webdriver.Chrome(service=service, options=chrome_options)
url = f'https://www.google.com/finance/quote/{ticker}:US'
driver.get(url)
# Example: Extract the current price
price_element = driver.find_element(By.CLASS_NAME, 'kf1m0')
price = price_element.text
print(f'Current price of {ticker}: {price}')
driver.quit()
# Example usage
ticker_symbol = 'AAPL'
scrape_google_finance_selenium(ticker_symbol)
This code snippet uses Selenium to launch a Chrome browser (in headless mode), navigate to the Google Finance page, and extract the current price. The find_element method is used to locate the element by its class name.
Extracting Historical Data
Google Finance also provides historical data for stocks. To scrape Google Finance with Python for historical data, you’ll need to navigate to the historical data section of the Google Finance page and extract the data from the table.
Here’s an example using BeautifulSoup and Pandas to extract historical data:
import requests
from bs4 import BeautifulSoup
import pandas as pd
def scrape_historical_data(ticker):
url = f'https://www.google.com/finance/quote/{ticker}:US?window=MAX'
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.content, 'html.parser')
# Find the historical data table (you may need to adjust the selector)
table = soup.find('table', class_='W2Dc2d')
if table:
# Extract data from the table
data = []
rows = table.find_all('tr')
for row in rows[1:]:
cols = row.find_all('td')
cols = [col.text.strip() for col in cols]
data.append(cols)
# Create a Pandas DataFrame
df = pd.DataFrame(data, columns=['Date', 'Open', 'High', 'Low', 'Close', 'Volume', 'Change'])
print(df)
else:
print('Historical data table not found.')
# Example usage
ticker_symbol = 'AAPL'
scrape_historical_data(ticker_symbol)
This code snippet fetches the HTML content of the historical data page, finds the table containing the historical data, and extracts the data into a Pandas DataFrame. The DataFrame provides a convenient way to manipulate and analyze the data.
Handling Pagination
If the historical data is paginated, you’ll need to handle pagination to extract all the data. This involves identifying the URL pattern for each page and iterating through the pages to extract the data. You can use a loop to construct the URLs for each page and then use requests and BeautifulSoup to extract the data from each page.
Respecting Robots.txt and Ethical Considerations
Before you scrape Google Finance with Python, it’s crucial to respect the website’s robots.txt file. This file specifies which parts of the website are allowed to be crawled and which are not. You can find the robots.txt file at the root of the website (e.g., https://www.google.com/robots.txt). Adhering to the robots.txt file is essential for ethical web scraping.
Additionally, avoid making excessive requests to the website, as this can overload the server and potentially lead to your IP address being blocked. Implement delays between requests to avoid overwhelming the server. Consider using proxies to distribute your requests and further reduce the risk of being blocked.
Common Challenges and Solutions
IP Blocking: If your IP address is blocked, try using proxies or implementing delays between requests.
Website Structure Changes: Websites often change their structure, which can break your scraping code. Regularly update your code to adapt to these changes.
Dynamic Content: Use Selenium to handle dynamic content loaded with JavaScript.
Rate Limiting: Respect the website’s rate limits by implementing delays between requests.
Data Cleaning: Clean and preprocess the scraped data to ensure its accuracy and consistency.
Storing and Analyzing Scraped Data
Once you’ve scraped the data, you’ll likely want to store it for further analysis. Common storage options include:
- CSV Files: Simple and widely compatible format for storing tabular data.
- Databases: Relational databases (e.g., MySQL, PostgreSQL) or NoSQL databases (e.g., MongoDB) for structured storage and querying.
- Data Warehouses: Cloud-based data warehouses (e.g., Amazon Redshift, Google BigQuery) for large-scale data storage and analysis.
You can use Pandas to easily write your scraped data to a CSV file or load it into a database. For example:
df.to_csv('google_finance_data.csv', index=False)
Once the data is stored, you can use various data analysis tools and techniques to gain insights, such as:
- Descriptive Statistics: Calculate summary statistics (e.g., mean, median, standard deviation) to understand the distribution of the data.
- Time Series Analysis: Analyze trends and patterns in the data over time.
- Machine Learning: Build predictive models to forecast future stock prices or identify investment opportunities.
Advanced Techniques
Asynchronous Scraping: Use asynchronous programming to make multiple requests concurrently, improving the speed of your scraping process.
Headless Browsers: Run Selenium in headless mode to avoid opening a visible browser window.
Proxy Rotation: Rotate through a list of proxies to avoid IP blocking.
Conclusion
Scrape Google Finance with Python offers a powerful and efficient way to access real-time financial data for analysis and decision-making. By following the steps outlined in this guide, you can automate the process of extracting data from Google Finance and integrate it into your existing workflows. Remember to respect the website’s robots.txt file and implement ethical scraping practices to avoid any legal or ethical issues. With the right tools and techniques, you can unlock valuable insights from Google Finance and gain a competitive edge in the financial market. Always remember to check the terms of service for Google Finance before scraping data and ensure you are complying with their policies. Using Python to scrape Google Finance with Python requires care and responsibility.
[See also: Python Web Scraping Tutorial]
[See also: Data Analysis with Pandas]
[See also: Selenium Automation Guide]
