Web Scraping vs. API: Choosing the Right Data Extraction Method
In today’s data-driven world, accessing and utilizing information from the web is crucial for various applications, from market research and competitive analysis to building innovative services. Two primary methods for extracting this data are web scraping and using Application Programming Interfaces (APIs). Understanding the differences, advantages, and disadvantages of web scraping vs API is essential for making informed decisions about which approach best suits your specific needs.
This article provides a comprehensive comparison of web scraping vs API, exploring their technical aspects, legal considerations, and practical applications. We’ll delve into when to use each method, the challenges involved, and the best practices for ethical and efficient data extraction. By the end, you’ll have a clear understanding of which data extraction technique – web scraping or API – is the right choice for your project.
Understanding Web Scraping
Web scraping, also known as web harvesting or web data extraction, is the process of automatically extracting data from websites. It involves using software or scripts to parse the HTML code of a webpage and extract specific pieces of information. This data is then typically stored in a structured format, such as a CSV file, database, or spreadsheet.
How Web Scraping Works
Web scraping tools work by sending HTTP requests to web servers, retrieving the HTML content of the requested pages, and then parsing the HTML to locate and extract the desired data. This process often involves using regular expressions, XPath queries, or CSS selectors to identify specific elements within the HTML structure.
The basic steps involved in web scraping are:
- Request: The scraper sends an HTTP request to the target website.
- Response: The website’s server responds with the HTML content of the page.
- Parsing: The scraper parses the HTML content to identify the elements containing the desired data.
- Extraction: The scraper extracts the data from the identified elements.
- Storage: The extracted data is stored in a structured format.
Advantages of Web Scraping
- Accessibility: Web scraping can be used to extract data from virtually any website, even if it doesn’t offer an official API.
- Customization: Scrapers can be customized to extract specific data elements, providing a high degree of control over the extracted information.
- Cost-effectiveness: Web scraping can be a cost-effective solution for extracting large amounts of data, especially compared to paying for API access.
Disadvantages of Web Scraping
- Fragility: Web scraping scripts can be fragile and prone to breaking if the target website changes its HTML structure.
- Legality and Ethics: Web scraping can raise legal and ethical concerns, particularly if it violates a website’s terms of service or places excessive load on its servers.
- Maintenance: Web scraping scripts require ongoing maintenance to ensure they continue to function correctly as websites evolve.
- Scalability: Scaling web scraping operations can be challenging, requiring robust infrastructure and sophisticated techniques to avoid detection and blocking.
Understanding APIs
An Application Programming Interface (API) is a set of rules and specifications that software programs can follow to communicate with each other. In the context of data extraction, APIs provide a structured and standardized way to access data from a specific source.
How APIs Work
APIs typically use standard protocols like HTTP and data formats like JSON or XML to exchange information. Developers can send requests to an API endpoint to retrieve specific data or perform certain actions. The API then processes the request and returns the requested data in a structured format.
The basic steps involved in using an API are:
- Authentication: The application authenticates with the API using an API key or other credentials.
- Request: The application sends an HTTP request to the API endpoint, specifying the desired data or action.
- Processing: The API processes the request and retrieves the requested data.
- Response: The API returns the data in a structured format, such as JSON or XML.
- Parsing: The application parses the data and uses it as needed.
Advantages of APIs
- Reliability: APIs are typically more reliable than web scraping because they are designed to provide stable and consistent access to data.
- Efficiency: APIs are optimized for data retrieval, making them more efficient than web scraping, which involves parsing entire HTML pages.
- Legality and Ethics: Using an API is generally considered more ethical and legal than web scraping, as it adheres to the website’s terms of service.
- Security: APIs often provide security features such as authentication and authorization to protect data from unauthorized access.
Disadvantages of APIs
- Availability: Not all websites offer APIs, limiting the availability of data that can be accessed in this way.
- Cost: Some APIs require payment for access, which can be a significant expense for large-scale data extraction projects.
- Limitations: APIs may have limitations on the amount of data that can be accessed or the frequency of requests, which can restrict the scope of data extraction.
- Complexity: Using APIs can require technical expertise and familiarity with API documentation and protocols.
Web Scraping vs. API: Key Differences
The following table summarizes the key differences between web scraping vs API:
| Feature | Web Scraping | API |
|---|---|---|
| Data Source | Any website | Websites with APIs |
| Data Format | Unstructured (HTML) | Structured (JSON, XML) |
| Reliability | Low | High |
| Efficiency | Low | High |
| Legality & Ethics | Potentially problematic | Generally acceptable |
| Maintenance | High | Low |
| Cost | Potentially lower upfront | Potentially higher, depending on usage |
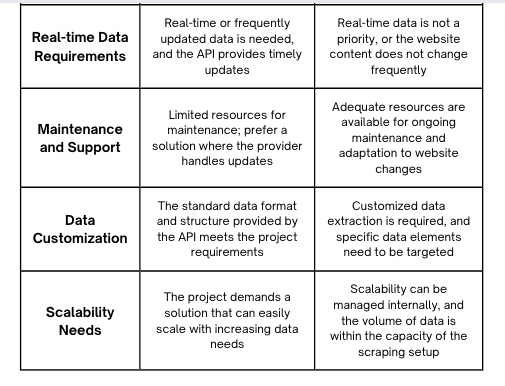
When to Use Web Scraping
Web scraping is a suitable option in the following scenarios:
- No API Available: When the website you want to extract data from doesn’t offer an official API.
- Specific Data Requirements: When you need to extract specific data elements that are not available through an API.
- Limited Budget: When you have a limited budget and cannot afford to pay for API access.
- Small-Scale Projects: For small-scale projects where the risk of breaking the scraper is low and the maintenance overhead is manageable.
When to Use APIs
APIs are the preferred option in the following scenarios:
- API Availability: When the website you want to extract data from offers a well-documented and reliable API.
- Large-Scale Projects: For large-scale projects where reliability and efficiency are critical.
- Legal and Ethical Considerations: When you want to ensure that your data extraction practices are legal and ethical.
- Data Consistency: When you need consistent and up-to-date data.
Legal and Ethical Considerations
Both web scraping and API usage raise legal and ethical considerations. It’s crucial to respect the terms of service of the websites you are extracting data from and to avoid placing excessive load on their servers. [See also: Data Privacy and GDPR Compliance]
Web scraping can be particularly problematic if it violates a website’s terms of service, infringes on copyright, or scrapes personal data without consent. It’s essential to consult with legal counsel to ensure that your web scraping practices are compliant with applicable laws and regulations.
Using APIs is generally considered more ethical and legal because it involves accessing data in a manner that the website owner has explicitly authorized. However, it’s still important to respect the API’s rate limits and usage guidelines to avoid overloading the server or violating the terms of service.
Best Practices for Web Scraping
If you choose to use web scraping, follow these best practices to minimize the risk of legal and ethical issues and to ensure the efficiency and reliability of your scraper:
- Respect robots.txt: Check the website’s robots.txt file to identify which pages are disallowed from scraping.
- Implement delays: Introduce delays between requests to avoid overloading the server.
- Use proxies: Rotate your IP address using proxies to avoid being blocked.
- Handle errors gracefully: Implement error handling to gracefully handle unexpected responses or changes in the website’s structure.
- Monitor performance: Monitor the performance of your scraper to identify and address any issues that may arise.
- Use a user-agent: Set a descriptive user-agent to identify your scraper to the website administrator.
Best Practices for Using APIs
If you choose to use an API, follow these best practices to ensure efficient and reliable data extraction:
- Read the documentation: Carefully read the API documentation to understand the available endpoints, parameters, and rate limits.
- Use authentication: Properly authenticate with the API using your API key or other credentials.
- Handle errors: Implement error handling to gracefully handle API errors and retry requests as needed.
- Respect rate limits: Respect the API’s rate limits to avoid being throttled or blocked.
- Cache data: Cache frequently accessed data to reduce the number of API requests.
- Monitor usage: Monitor your API usage to track your costs and identify any potential issues.
Conclusion
Choosing between web scraping vs API depends on your specific needs and circumstances. APIs are generally the preferred option when available, as they offer a more reliable, efficient, and ethical way to access data. However, web scraping can be a viable alternative when APIs are not available or when you need to extract specific data elements that are not accessible through an API. By understanding the differences, advantages, and disadvantages of each method, you can make an informed decision about which approach best suits your data extraction requirements. Remember to always prioritize ethical and legal considerations when extracting data from the web. When deciding between web scraping vs API consider the long-term maintenance, scalability, and legal implications of each approach. Carefully weighing these factors will lead to a more sustainable and responsible data extraction strategy. [See also: Building a Data-Driven Business Strategy]
