Website Data Extraction: Unlocking Insights for Business Growth
In today’s data-driven world, businesses are constantly seeking ways to gain a competitive edge. One powerful method for achieving this is through website data extraction. This process, also known as web scraping, involves automatically collecting data from websites and storing it in a structured format for analysis. Effectively implemented, website data extraction can provide invaluable insights into market trends, competitor activities, customer behavior, and much more.
This article delves into the world of website data extraction, exploring its benefits, methods, ethical considerations, and best practices. Whether you are a seasoned data scientist or a business owner looking to leverage data for growth, this guide will provide you with a comprehensive understanding of this powerful technique.
What is Website Data Extraction?
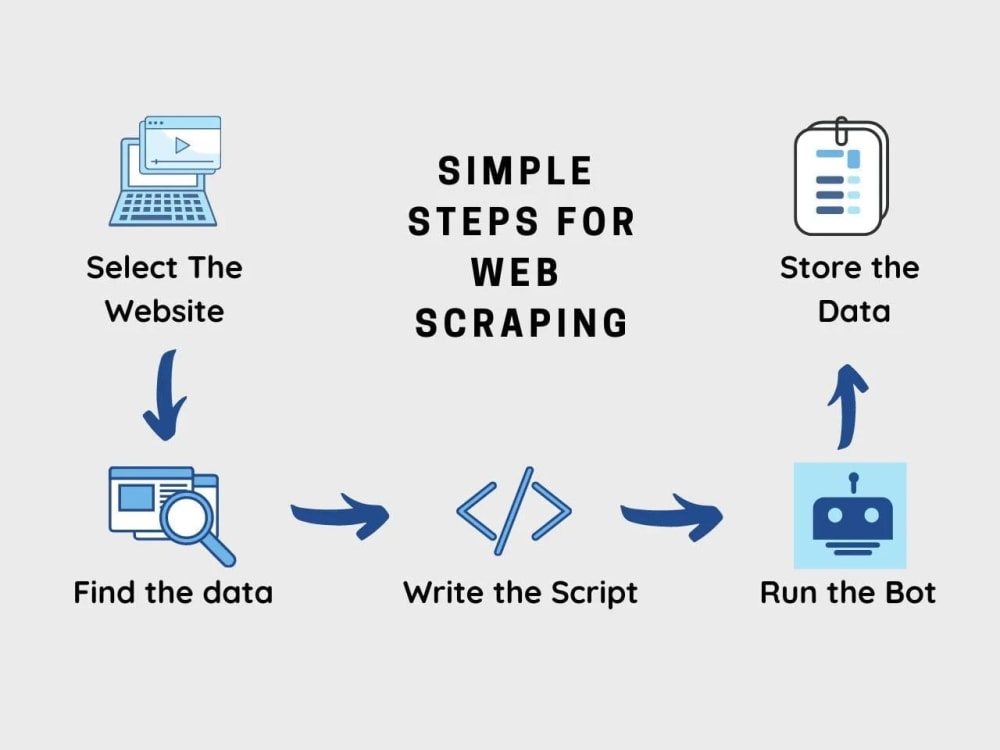
Website data extraction is the automated process of gathering data from websites. Unlike manual data collection, which is time-consuming and prone to errors, website data extraction utilizes specialized tools and techniques to efficiently extract large volumes of information. This extracted data can then be used for a variety of purposes, including market research, lead generation, price monitoring, and content aggregation.
The process typically involves using a web scraper, which is a software program designed to navigate websites, identify specific data points, and extract them. These scrapers can be customized to target specific elements on a webpage, such as text, images, links, and tables. The extracted data is then typically stored in a structured format, such as a CSV file, Excel spreadsheet, or database, making it easy to analyze and utilize.
Benefits of Website Data Extraction
The benefits of website data extraction are numerous and can significantly impact various aspects of a business. Here are some key advantages:
- Market Research: Extracting data from competitor websites, industry portals, and online forums can provide valuable insights into market trends, customer preferences, and competitor strategies.
- Lead Generation: Website data extraction can be used to identify potential leads by scraping contact information from websites and online directories. This can significantly streamline the lead generation process and improve sales efficiency.
- Price Monitoring: E-commerce businesses can use website data extraction to monitor competitor pricing and adjust their own pricing strategies accordingly. This helps maintain competitiveness and maximize profitability.
- Content Aggregation: News organizations and content creators can use website data extraction to aggregate content from various sources, creating a comprehensive and up-to-date information repository.
- Data-Driven Decision Making: By providing access to large volumes of structured data, website data extraction enables businesses to make more informed decisions based on factual evidence rather than intuition.
Methods of Website Data Extraction
There are several methods for performing website data extraction, each with its own advantages and disadvantages. Here are some of the most common approaches:
Manual Copy-Pasting
This is the most basic method and involves manually copying and pasting data from websites into a spreadsheet or document. While simple, this method is extremely time-consuming and impractical for extracting large amounts of data. It is also prone to errors and inconsistencies.
Regular Expressions (Regex)
Regular expressions are a powerful tool for pattern matching and can be used to extract specific data from text-based websites. This method requires a good understanding of regex syntax and can be challenging for complex websites with dynamic content.
HTML Parsing
HTML parsing involves using programming languages like Python with libraries such as Beautiful Soup or Scrapy to parse the HTML structure of a website and extract specific data elements. This method is more efficient than regex and can handle more complex websites.
Web Scraping Tools
Web scraping tools are specialized software applications designed specifically for website data extraction. These tools typically provide a user-friendly interface and pre-built features for extracting data from websites. Some popular web scraping tools include Octoparse, ParseHub, and Apify.
APIs (Application Programming Interfaces)
Some websites offer APIs that allow developers to access their data in a structured and controlled manner. Using APIs is generally the most reliable and ethical way to extract data from websites, as it respects the website’s terms of service and avoids overloading the server.
Ethical Considerations and Legal Aspects
While website data extraction can be a powerful tool, it is important to consider the ethical and legal implications. Scraping websites without permission can violate their terms of service and potentially lead to legal action. It is also important to avoid overloading a website’s server with excessive scraping requests, as this can disrupt its performance and negatively impact its users.
Here are some ethical guidelines to follow when performing website data extraction:
- Respect Terms of Service: Always review the website’s terms of service before scraping to ensure that you are not violating any rules.
- Obtain Permission: If possible, obtain permission from the website owner before scraping their data.
- Use APIs When Available: If the website offers an API, use it instead of scraping.
- Rate Limiting: Implement rate limiting to avoid overloading the website’s server with excessive requests.
- Identify Yourself: Include a user-agent string in your scraper to identify yourself to the website server.
- Respect Robots.txt: The robots.txt file specifies which parts of the website should not be crawled by robots. Always respect these directives.
Best Practices for Website Data Extraction
To ensure that your website data extraction efforts are successful and ethical, follow these best practices:
- Plan Your Project: Clearly define your goals, target websites, and data requirements before starting the extraction process.
- Choose the Right Tool: Select a web scraping tool or method that is appropriate for the complexity of the website and your technical skills.
- Handle Dynamic Content: Websites with dynamic content may require more sophisticated scraping techniques, such as using headless browsers or handling JavaScript rendering.
- Clean and Validate Data: After extracting the data, clean it and validate it to ensure accuracy and consistency.
- Store Data Securely: Store the extracted data in a secure location to protect it from unauthorized access.
- Monitor Your Scrapers: Regularly monitor your scrapers to ensure that they are working correctly and not causing any issues for the target websites.
- Adapt to Changes: Websites can change their structure and content frequently, so be prepared to adapt your scrapers accordingly.
Tools for Website Data Extraction
Several tools are available for website data extraction, ranging from simple browser extensions to sophisticated software platforms. Here are some popular options:
- Octoparse: A user-friendly web scraping tool with a visual interface and pre-built templates for extracting data from various websites.
- ParseHub: Another popular web scraping tool with a visual interface and support for dynamic websites.
- Apify: A cloud-based web scraping platform that allows you to build and deploy scrapers at scale.
- Scrapy: A powerful Python framework for building web scrapers. It is highly customizable and suitable for complex scraping tasks.
- Beautiful Soup: A Python library for parsing HTML and XML documents. It is often used in conjunction with Scrapy to extract data from websites.
- Selenium: A web automation framework that can be used to control web browsers and extract data from dynamic websites.
Real-World Applications of Website Data Extraction
Website data extraction is used across a wide range of industries and applications. Here are some examples:
- E-commerce: Price monitoring, product research, competitor analysis.
- Finance: Stock market data, financial news, economic indicators.
- Marketing: Lead generation, social media monitoring, brand reputation analysis.
- Real Estate: Property listings, market trends, investment opportunities.
- Journalism: News aggregation, fact-checking, investigative reporting.
The Future of Website Data Extraction
As the amount of data on the web continues to grow, website data extraction will become even more important for businesses and organizations seeking to gain a competitive edge. Advancements in artificial intelligence and machine learning are making it easier to extract data from complex websites and analyze it in more sophisticated ways.
However, it is also important to address the ethical and legal challenges associated with website data extraction. As websites become more sophisticated in their efforts to prevent scraping, it will be increasingly important to use ethical and responsible scraping techniques that respect the rights of website owners and users.
In conclusion, website data extraction is a powerful tool that can provide valuable insights for businesses and organizations. By understanding the benefits, methods, ethical considerations, and best practices, you can leverage this technique to unlock the full potential of web data and drive growth.
[See also: Ethical Web Scraping Practices]
[See also: Web Scraping for Market Research]
